- Deda
- Investor
- Media
- Careers
- Blog
- Deda
- Investor
- Media
- Careers
- Blog
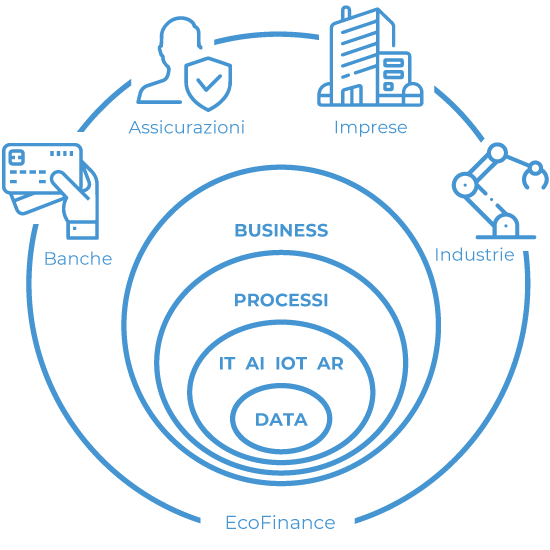
Raccogliamo le sfide che i nostri clienti affrontano ogni giorno, rilanciandole verso nuovi livelli evolutivi, concretizziamo le loro esigenze integrandole nell’operatività dei processi fino allo sviluppo di nuovi modelli di business.
Partendo dalla governance e l'analisi intelligente del Dato, disegniamo soluzioni e infrastrutture utilizzando le tecnologie più innovative per supportare la Digital Transformation e la Business Innovation di Banche, Assicurazioni, Large Corporate e Industrie.
La soluzione per la Smart Process Automation
La soluzione innovativa per la gestione tesoreria per gli Enti Pubblici.











